Overview
The agave client deserializes transactions from the network using serde and bincode. However, the transaction types have internal vectors, which are stored on the heap. Allocating these numerous and small vectors on the heap is by far the most time-consuming part of ingesting transaction into the scheduler thread.
Why do we care? Deserialization being slow is a bottleneck for the transaction scheduler in the block-production code. The longer it takes to deserialize transactions, the less time we have to find and schedule the optimal transactions for the block. The scheduler can only schedule transactions that it has knowledge of, and in our current system, that means only after this deserialization.
What can we do? The first thing we can try is to change the way we deserialize transactions to avoid any heap allocations. It’s likely a big lift to replace our transaction type with a new one. So before we do that, we should justify the cost of doing so.
Serialized Transactions
Let’s start off with what a serialized transaction even looks like. A simple transfer, generated with
rustsystem_transaction::transfer(mint_keypair, &pubkey0, 1, genesis_config.hash())would have raw bytes that look like this:
01 E0 2C 5B 58 B6 13 8E 61 EE 11 18 15 81 08 5E 95 3F 3A 42 5A 3D 23 4F 4D CD A7 1F 0E 3A BC 3A
DB 5C 1B 95 4F 84 3A 1E B0 51 9B F2 2E D8 DD 17 C3 A0 6C E3 C6 41 CC F2 67 5C CE A0 33 9E 3E 8B
0D 01 00 01 03 B5 4C 30 EC 53 BE 6B CB A5 B4 D8 57 10 A1 5E 8F 2E 30 5E F9 D3 7C CF E9 F3 C6 6C
D7 BF E2 2F 85 63 40 7A 6D 60 DE 0F AD D8 D1 E5 E4 B5 5A 38 C5 C0 F2 32 A6 DA D6 52 6A C6 0E 4F
D5 39 48 CB 7E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 14 28 E0 7D D9 EC FB 12 2D 23 50 6E 2A B6 C7 89 B3 A8 6B F7 24 73 6D A4 21 F2 78
CF 7A 1F 6D 32 01 02 02 00 01 0C 02 00 00 00 01 00 00 00 00 00 00 00Here’s a simple diagram to show what the above bytes represent:
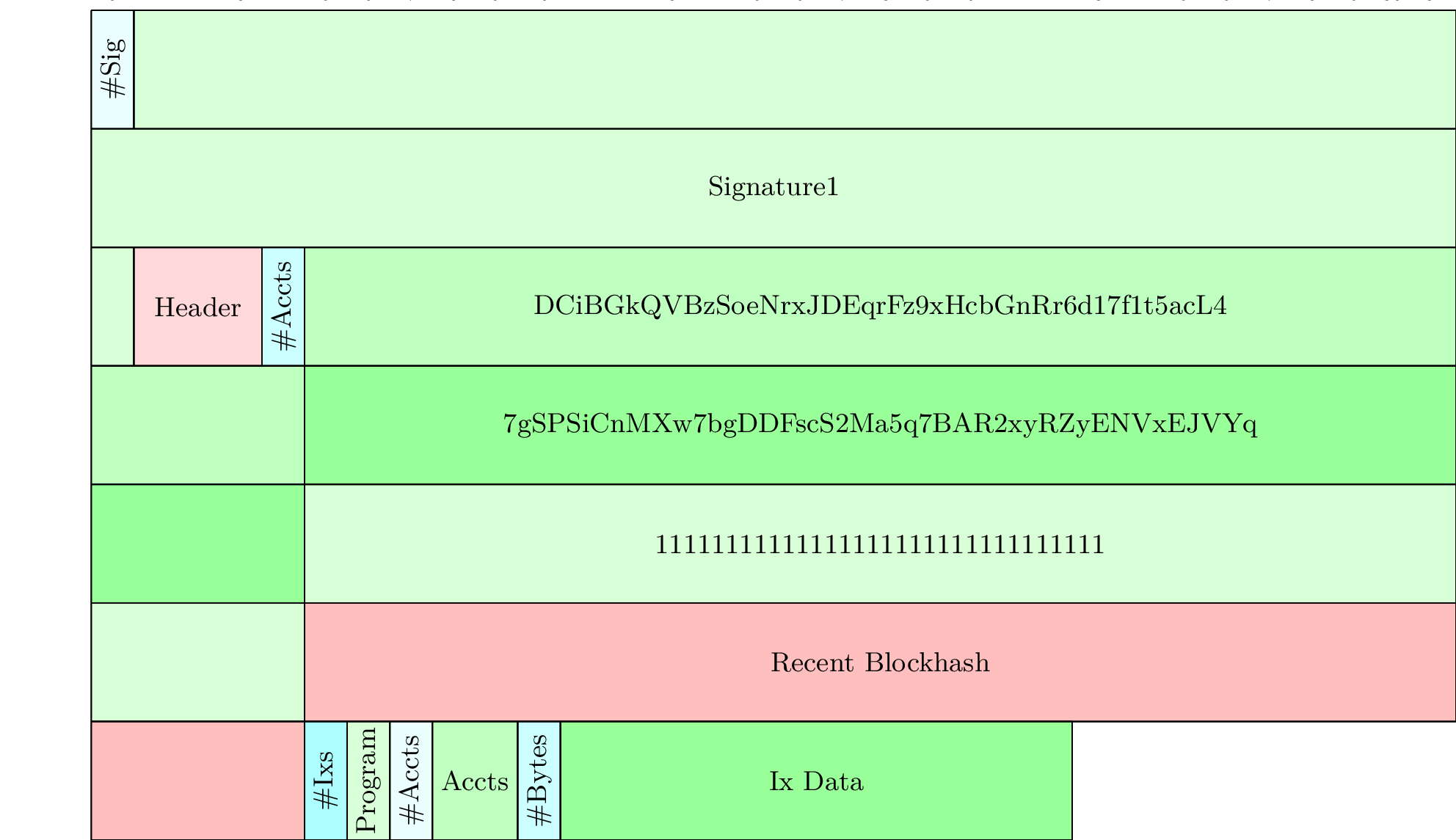
Luckily all the types in the serialized transaction are simply arrays or vectors of bytes, meaning they are all alignment 1. The exception to this are the lengths of our various vectors, which are a u16; however, a custom encoding is used for these lengths to minimize the number of bytes used.
From this format, it appears “deserializing” a transaction could be as simple as keeping a few offsets and lengths into these raw bytes. That shouldn’t be expensive at all, so why is it?
First let’s look at the simplified structures for the transaction and all internal types are shown below:
rustpub struct VersionedTransaction {
pub signatures: Vec<Signature>,
pub message: VersionedMessage,
}
pub enum VersionedMessage {
Legacy(LegacyMessage),
V0(v0::Message),
}
pub struct Message {
pub header: MessageHeader,
pub account_keys: Vec<Pubkey>,
pub recent_blockhash: Hash,
pub instructions: Vec<CompiledInstruction>,
}
pub struct v0::Message {
pub header: MessageHeader,
pub account_keys: Vec<Pubkey>,
pub recent_blockhash: Hash,
pub instructions: Vec<CompiledInstruction>,
pub address_table_lookups: Vec<MessageAddressTableLookup>,
}
pub struct MessageHeader {
pub num_required_signatures: u8,
pub num_readonly_signed_accounts: u8,
pub num_readonly_unsigned_accounts: u8,
}
pub struct Pubkey(pub(crate) [u8; 32]);
pub struct CompiledInstruction {
pub program_id_index: u8,
pub accounts: Vec<u8>,
pub data: Vec<u8>,
}
pub struct MessageAddressTableLookup {
pub account_key: Pubkey,
pub writable_indexes: Vec<u8>,
pub readonly_indexes: Vec<u8>,
}The above structures lead to many, typically small, heap allocations. For a simple transfer we have 5 heap allocations, below are the details:
signatures: Vec<Signature>account_keys: Vec<Pubkey>instructions: Vec<CompiledInstruction>:- for each
CompiledInstruction:accounts: Vec<u8>data: Vec<u8>
In general legacy transactions use 3 + 2 * num_instructions heap allocations, and v0 transactions would use 4 + 2 * num_instructions + 2 * num_lookups.
Everytime we do a heap allocation, or when we eventually drop these transaction types, we are risking an occasionally long call to the allocator. This is the primary reason why this deserialization is slow.
Custom allocators could be a solution here.
Custom Allocators
The first idea I explored was using rust’s unstable allocator feature. Simply have a buffer of sufficient size to hold the transaction, and use this buffer to allocate the Vecs of our transaction. This would be a big win, as we could avoid the heap allocations entirely, and a simple bump allocator would be sufficient since we do not resize.
A couple of downsides to this approach:
- We need to use nightly rust, which is not ideal for the project.
- The allocator feature is unstable, so it could change at any time.
- We lose the original packet layout, so serialization would still need to be done with serde and bincode.
On point 3, if using custom allocators, our buffer cannot have the same layout as the original packet for a couple of reasons.
Mainly the problem comes from the Vec<u8> within the CompiledInstruction.
In the serialization format, those bytes are written inline so the CompiledInstructions in that vector are not a fixed size!
These internal fields would likely have to be after the Vec<CompiledInstruction> allocation in the buffer.
That’s not necessarily a deal breaker, but it is a downside.
A New Transaction Type
What if we just start from scratch? Let’s just take ownership of the packet, do some sanity checks on the lengths within that packet, and then just calculate and store lengths and offsets into that packet. This would allow us to avoid heap allocations entirely, keep the original packet layout, and avoid the need for nightly rust!
Replacing the current transaction type with a new one is quite a task. It means updating every place where we currently use the old type and making sure the new type works seamlessly with the existing code. We’ve been working on ways to either replace or add more features to our transaction type to include extra metadata. If we decide not to take the simpler route of just wrapping the current type, we need to prove that the new type is worth the effort.
A new transaction type could be structured this ways:
rustpub struct TransactionView {
packet: Packet,
signature_len: u16,
signature_offset: u16,
num_required_signatures: u8,
num_readonly_signed_accounts: u8,
num_readonly_unsigned_accounts: u8,
version: TransactionVersion,
message_offset: u16,
static_accounts_len: u16,
static_accounts_offset: u16,
recent_blockhash_offset: u16,
instructions_len: u16,
instructions_offset: u16,
address_offsets_len: u16,
address_offsets_offset: u16,
}Benchmarks
To show the improvement, let’s benchmark deserialization of simple transactions. We generate a bunch of transactions, serialize into packets, then loop over those packets in batches of 192. We then deserialize each packet into a transaction, and measure the time it takes to do so.
rust bencher.iter(|| {
let packet_batch = packet_batch_iterator.next().unwrap();
for (idx, packet) in packet_batch.iter().enumerate() {
// Old transaction type - deserialize and sanitize.
let _ = SanitizedVersionedTransaction::try_new(
test::black_box(packet.clone())
.deserialize_slice::<VersionedTransaction, _>(..)
.unwrap(),
)
.unwrap();
// Create new buffer and populate with packet data, then sanitize.
// let mut transaction_view = TransactionView::try_new(test::black_box(&packet)).unwrap();
// transaction_view.sanitize().unwrap();
// Re-use buffers from a pool, populate with packet data, then sanitize.
// transaction_views[idx]
// .populate_from(test::black_box(packet))
// .unwrap();
// transaction_views[idx].sanitize().unwrap();
}
});We can comment/uncomment lines in the above to test the new transaction type and compare with the old.
Initial Benchmark Results
| Deserialization Method | Transaction Type | Time-per-batch (ns) | Time-per-packet (ns) |
|---|---|---|---|
| VersionedTransaction | multi_accounts | 70107 | 365 |
| VersionedTransaction | multi_programs | 138590 | 721 |
| TransactionView | multi_accounts | 35287 | 183 |
| TransactionView | multi_programs | 45589 | 237 |
| TransactionView (pool) | multi_accounts | 6500 | 34 |
| TransactionView (pool) | multi_programs | 14198 | 74 |
These initial results are extremely promising, we are seeing a near 10x speedup in deserialization time. This does not mean we can get 10x more TPS - but it does mean the scheduler will have less jitter, more time to schedule transactions, and more likely to get the best transactions into the block.
This was a simple benchmark, but how do things hold up in a more realistic scenario? Since the point of these benchmarks/testing is so we don’t have to rip out and replace the transaction type everywhere quite yet… my strategy was to modify banking stage to simply receive, deserialize, and buffer transactions. We can then run bench-tps on this modified version of the code and see how long it takes to receive, deserialize, and buffer the transactions under load.
Bench-TPS Results
The implementation of this is still ongoing, but uses the (pool) approach for TransactionView storage.
When using either transaction type, the scheduling thread keeps up with the incoming transactions, so there’s nothing left in the channel from sigverify.
We can compare how much time it is taking to do the deserialization and buffering of transactions in order to see the improvement.
Each of the benchmarks is running over time and there’s some variation in the timing and exact number of packets but they reach an effective steady-state. The results are shown in some metric plots below.
VersionedTransaction:

TransactionView:

Receiving roughly the same number of transactions at the same rate, we see we spend only 2ms deserializing and buffering transactions with the new transaction type. The old transaction type using bincode/serde takes 122ms to do the same work. This is a massive improvement, and in my opinion justifies the effort to use this new transaction type (or something very similar). Beyond just the improvements in banking stage, it also means there are fewer allocations in the system overall which could have knock-on effects improving performance elsewhere.
Plan to Implement
- Create an interface trait for a generic transaction type
- Implement the trait for the old transaction type
- Make all checks and processing functions generic over the interface trait
- Implement the new transaction type and the trait for it
- Update scheduler code to use the new transaction type