This post is a long-form explainer on the historic, current, and near-term scheduling algorithms and design used in the Solana Labs validator client’s block-production.
Background - Block-Production
At the beginning of each epoch, the cluster creates a leader schedule for the
entire epoch.
This leader schedule is determined by the stake-weight of each validator, and
allocates groups of 4 slots to validators in proportion to their stake-weight.
During the slot(s) allocated to a validator, that validator is the leader and
is responsible for creating a block and broadcasting it to the rest of the
network.
This process of creating the block is referred to as “block-production”, and
within the Solana Labs’ client as BankingStage.
Each block is created from sets of transactions that are received from users and other validators in the network. However, there are limits on the amount of work a block is allowed to contain, because each block is intended to executed within 400ms. Often the leader will receive many more transactions that can actually be included within a block, and so the leader must decide which transactions to include.
Entry Constraints
Historic designs were limited by certain constaints and it is important to mention these constraints. While there as plans to remove some of these constraints, they are still relevant to explanation of previous and current designs.
The Solana transaction history is composed of a series of entries. Each entry is a list of transactions. However, an entry cannot contain conflicting transactions; if it does, then the entire block will be marked as invalid by the network.
Solana Labs’ Client Architecture
At a very high level, the Solana Labs’ block-production code sits between
signature verification (SigVerify), and broadcasting (BroadcastStage).
Historic Design
As this post will discuss the current and future block-production algorithms and design, it is useful to first understand previous designs.
Block-production within the Labs’ client has gone through many changes, but has histocially involved multiple nearly independent threads, each with their own queue of transactions, and each running their own scheduling. Here, scheduling refers to the process of deciding the order that transactions are processed in, and thus included into the block. While each thread is nearly independent, there is some coordination between the threads to ensure that conflicting transactions are not executed in parallel.
The historic and current designs have threads which access a shared channel to pull transactions from into their local queues. When pulled into the local queue, the transactions are sorted by priority. During block-production, each thread would take the top 128 transactions from their local queue, attempt to grab locks, then execute, record and commit the transactions. If the lock grab failed, the transaction would be retried at a later time.
Historic Design - Drawbacks
The historic design had several drawbacks, mainly related to failed lock grabs. During competitive events, such as NFT mints, the top of the queue is often filled with conflicting transactions. Given the entry constraints, this means each thread would attempt to lock 128 conflicting transactions, but fail to lock 127 of them. This resulted in massive inefficiency as the majority of transactions would be skipped over to be retried later. Additionally, because the other threads were also likely to be grabbing the same locks, only one thread may have actually been doing useful work.
At the point these drawbacks became issues, there were already plans for a more advanced scheduling design, but there was urgency to address the issues in the short-term. This urgency led to the introduction of the multi-iterator approach.
The multi-iterator approach is still used in the current algorithm, and leaves the architecture unchanged from the historic design. Since each thread maintains its’ own local queue, the current block-production method has been named “thread-local-multi-iterator”.
Thread-Local Multi-Iterator
What is the Multi-Iterator?
The multi-iterator is a class which takes a slice of items, and will march multiple iterators through the slice according to a decision-function that is passed in. The decision-function is responsible for determining whether an item should be processed immediately, on the next march of the iterators, or skipped entirely.
In the context of BankingStage, the multi-iterator is used to create batches
of non-conficting transactions.
Let’s take a look at iteration through an example, with a batch size of 2.
Let shared node color indicate conflicting transactions.
If we have several conflicting transactions at the beginning of our buffer,
the previous method would have attempted to lock both of these transactions
within the same batch.
Grabbing locks on the second one would have failed, and the second transaction
would then be retried later.
However, with the multi-iterator, we check locks against the in-progress batch before selection. The initial step will select the first transaction, then the second transaction will be skipped for this batch because it conflicts with the first. On the next multi-iterator iteration, the second transaction is selected by the first iterator marching forward.
How does the Multi-Iterator Help?
This leads to each of our BankingStage threads being able to create
non-conflicting batches, which eliminates most of the retryable transactions
that were previously seen during competitive events such as NFT mints.
This additionally allows lower-priority non-conflicting transactions to be
included into the block.
Thread-Local Multi-Iterator - Drawbacks
However, using the multi-iterator in this way does not eliminate all locking
conflicts, because each BankingStage thread has an independent buffer it is
iterating through.
Since packets are essentially pulled randomly by each BankingStage thread
from the shared channel from SigVerify, each BankingStage thread will have
a random set of all the transactions.
During competitive events, it is thus likely that the many high-priority
transactions will be in multiple BankingStage threads’ buffers, and this will
cause inter-thread locking conflicts.
There are also several edge cases in which transactions will be executed out of
priority order, which is not desirable.
This is a problem that can be addressed by changing BankingStage’s
architecture to use a single scheduling thread that sends transactions to
worker threads.
Central Scheduling Thread
The next step in the evolution of BankingStage is to move to a single
scheduling thread that sends work to worker threads.
This will allow the scheduling algorithm to determine which transactions can be
executed in parallel and send them to the appropriate thread.
There are corner-cases in the multi-iterator approach that lead to out of priority order execution for conflicting transactions. These issues were not easily resolvable while maintaining performance, and so a different approach has been taken for the central scheduling design.
Central Scheduling Architecture
An overview of the central scheduling BankingStage architecture is shown below.
In this architecture, the scheduler is the only thread which accesses the
channel from SigVerify.
The scheduler is responsible for pulling transactions from the receiver
channel, and sending them to the appropriate worker thread.
A decision was made to use separate channels between the scheduler and worker threads, rather than a single shared channel. This allows conflicting work to be queued onto the thread it conflicts with, which allows for overall better throughput. This is due to the overhead of communication between the worker thread and the scheduler, but is a decision that may be reversed in the future if overhead can be brought down.
The scheduler maintains a view of which account locks are in-use by which threads, and is able to determine which threads a transaction can be queued on. Each worker thread will process batches of transactions, in the received order, and send a message back to the scheduler upon completion of each batch. These messages back to the scheduler allow the scheduler to update its’ view of the locks, and thus determine which future transactions can be scheduled.
Scheduling Algorithm - Prio-Graph
The actual scheduling algorithm can be described in a relatively straight-forward way. During scheduling the highest-priority transactions are popped from the queue, and inserted into a lazily populated dependency graph, which we will refer to as a “prio-graph”. In this graph, edges are only present between a transaction and the next-highest priority transaction that conflicts with it per account. Initially, a “look-ahead” window of some reasonable length is popped from the priority queue and inserted into the graph. As the scheduler pops from the graph for actual scheduling, another transaction is popped from the priority queue and inserted into the graph. The graph structure allows us to look ahead and determine if currently non-conflicting transactions will eventually have depedent transactions that conflict, i.e. a graph join. If a graph join is detected, these transactions can be queued onto the same thread to avoid creating an unschedulable transaction in the near future. There is still work being done on tuning the size of the look-ahead window. A window that is too small will lead to many unschedulable transactions and delay execution more than necessary. A window that is too large will lead to many transactions being queued onto the same thread, and the advantages of parallelism are lost.
Visualization of Prio-Graph
The great thing about graphs is that they are easy to visualize. Thanks to banking-trace data collected by leader nodes, we can visualize the prio-graph for all received transactions within a slot.
An example visualization of the full prio-graph1 for slot 229666043 is shown in the following images.

Here there are 89 entirely distinct collections of transactions, which could be scheduled in parallel. Many of these groups are very small and only have a few transactions, or very simple sequential structure. However, the large groups are more interesting, and show a root-like structure.

If we zoom into the largest group, we can see it actually has three main branches, which ultimately join together with a few low-priority transactions. This is a good example of where the look-ahead window can be tuned, since if we had too large of a window, these three large branches may have been scheduled sequentially.
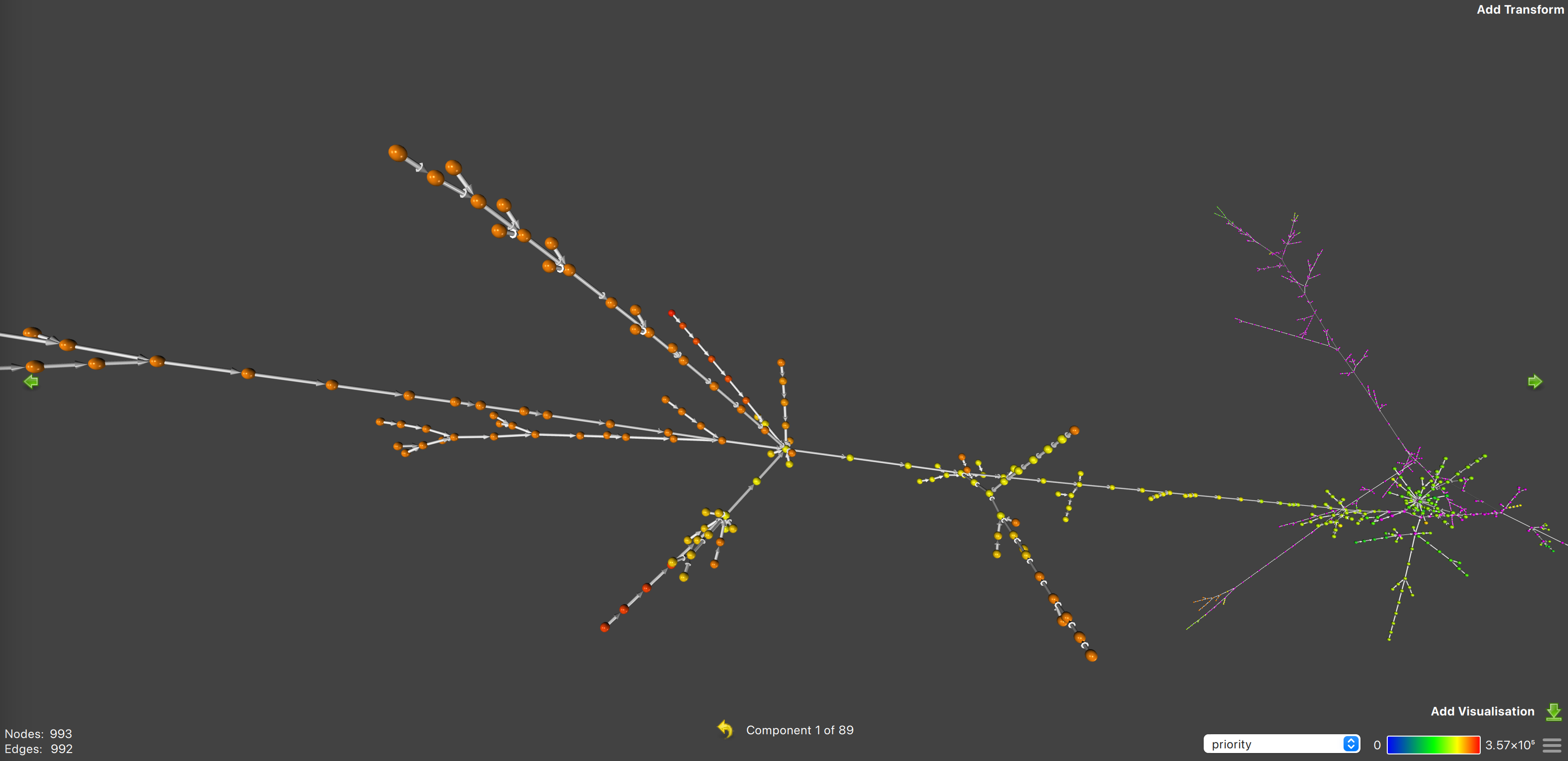
However, if we zoom further into some of the high-priority transactions on one of the main branches, we can see there are many transactions that are one removed from the branch. The look-ahead window is used to schedule these transactions onto the same thread as the main branch, so that we can avoid making some lower-priority, but still relatively high-priority, transactions unschedulable. By unschedulable, we mean that the transaction cannot be scheduled currently because it has outstanding conflicts with multiple threads.
The actual prio-graph is simplified here, with redundant edges removed to improve readability. ↩︎