Transaction Serialization Format
The Problem
In my last post, I described the transaction serialization format. That post was intended as an internal justification for pursuing a project to create a more efficient transaction parser. The project to create a more efficient parser is now underway, and this post serves to document my frustrations with the current serialization format and how we could do better.
After working with the current serialization format for a few weeks, the main grievances I have are due to the simple fact that we use inline serialization of variable length types. This presents itself in the form of two components:
- the instructions
- message address table lookups (these are only present for V0 transactions)
Let’s start with what “inline serialization” even means in this case.
Inline Serialization
pub struct Message {
pub header: MessageHeader,
#[serde(with = "short_vec")]
pub account_keys: Vec<Pubkey>,
pub recent_blockhash: Hash,
#[serde(with = "short_vec")]
pub instructions: Vec<CompiledInstruction>,
}The above code is how a legacy message is represented in the solana sdk.
When this is serialized, the length of instructions is serialized as a compressed u16 1.
Following that, the first instruction is serialized (in full), then the second, and so on.
The account_keys field is serialized in much the same way, but there’s not an issue with that because the Pubkey type is a fixed serialized size.
The issue comes because our CompiledInstruction type has internal variable length vectors.
pub struct CompiledInstruction {
pub program_id_index: u8,
#[serde(with = "short_vec")]
pub accounts: Vec<u8>,
#[serde(with = "short_vec")]
pub data: Vec<u8>,
}Each instruction is serialized as a byte, followed by a compressed u16, accounts.len() bytes, another compressed u16, and finally data.len() bytes.
If we had two instructions, this might look something like:
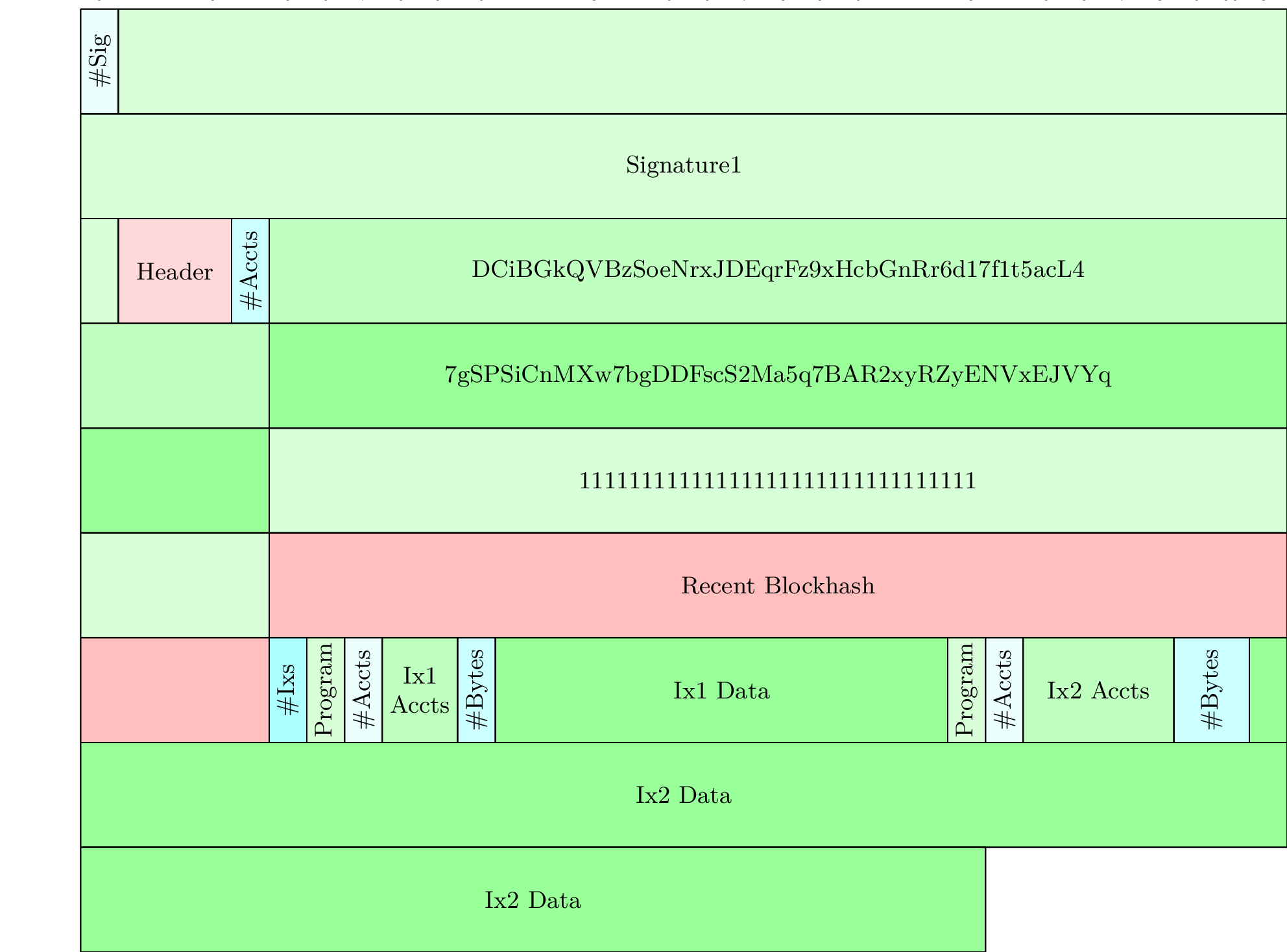
Beyond the fact that the bincode deserialization code forces us to do many small allocations, which is slow, this also makes some operations more difficult if we want use a zero-copy deserialization strategy. Without caching metadata about each instruction, there is no way to determine where the data for an instruction at a specific index is located in the serialized data - the only way to do this would be to reparse from the beginning of the instructions array. Additionally, caching metadata about each instruction comes with its own set of problems, such as using more memory and making the deserialization code more complex - particularly when there is not currently a simple limit on the number of instructions beyond the packet length.
Another issue is not strictly with the serialization format, but with the sanitization checks that are required for transactions.
One requirement for a transaction to even be considered for execution is that every account index in each CompiledInstruction must be a valid index - i.e. less than the number of accounts.
This is simple enough if we know the number of accounts, like we do in the Legacy transactions.
In V0 transactions, however, the number of accounts is not known until after the address_table_lookups are parsed.
pub struct Message {
pub header: MessageHeader,
#[serde(with = "short_vec")]
pub account_keys: Vec<Pubkey>,
pub recent_blockhash: Hash,
#[serde(with = "short_vec")]
pub instructions: Vec<CompiledInstruction>,
#[serde(with = "short_vec")]
pub address_table_lookups: Vec<MessageAddressTableLookup>,
}As the above code shows, the address_table_lookups are serialized after the instructions. This means to do the basic sanitization check, we need to parse our instructions to even figure out where the address_table_lookups begin. Then parse the address_table_lookups to get the total number of accounts. Then we can finally go back to loop over our instructions to check that all account indices are valid. But wait, I already mentioned that if we’re not caching instruction information this means we need to reparse all those instructions again to get the account indices and validate them. There has got to be a better way to do this!
Proposal - Out-of-band Serialization
Inline serialization seems like a sane way to have a compressed serialization format, and considering solana transactions are limited to a size of 1232 bytes it seems like a reasonable choice to make. However, as explained above, it comes at the cost of performance. There’s ongoing long-term work to increase the transaction size limit, so its’ possible the current neccessity for inline serialization will be removed. This may open the opportunity for a serialization format that is more efficient to parse and sanitize, at the cost of a few bytes overhead per instruction and ATL.
One way to do this would be to separate the serialization of internal data of the CompiledInstruction and MessageAddressTableLookup types from their arrays.
Instead, we could have a serialized array of offset structs that point to the start of each CompiledInstruction and MessageAddressTableLookup in the serialized data.
Consider something along the lines of:
struct CompiledInstructionOffset {
// This can be stored inline because the size is fixed
program_id_index: u8,
/// Offset to the start of the accounts array.
/// The offset is relative to the start of the transaction packet.
/// This value is in bytes.
/// Serialization order is accounts, then data.
accounts_and_data_offset: u16,
// The number of accounts in the accounts array.
// Array starts at `accounts_and_data_offset`.
accounts_len: u16,
// The number of bytes in the data array.
// Array starts at `accounts_data_data_offset` + `accounts_len`.
data_len: u16,
}This has a fixed size, so we can serialize this inline. The data pointed to by accounts_offset and data_offset would be serialized at the end of the transaction packet.
The same transaction as above, but serialized with this new format, might look something like:
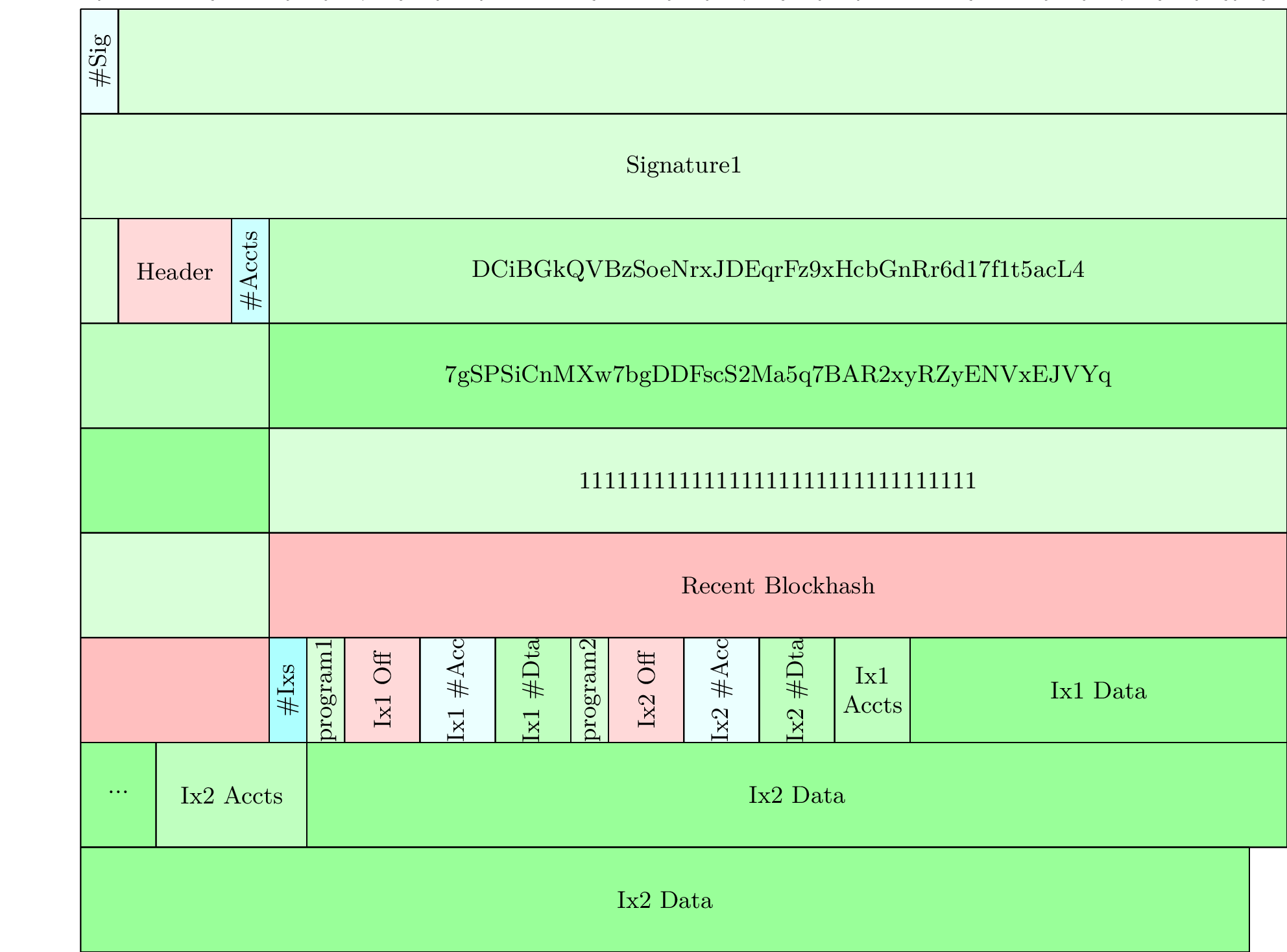
The resulting serialized transaction is 7 bytes larger than the previous serialization format. The primary benefit is any iteration over the instructions, which is a relatively common operation, can now be done more efficiently - a few pointer operations instead of re-parsing the compressed u16s each time.
There are a few challenges with this approach:
- the struct is 8 bytes, which is larger than the current 3 byte minimum and 7 byte maximum for a
CompiledInstruction(excluding the actual accounts and data) - the alignment of this struct is 2 bytes, so if we do not wish to copy these during the deserialization/parsing process we need to ensure the
CompiledInstructionOffsetarray is aligned to 2 bytes, which may come at the cost of a padding byte. - the offsets to data, which will be serialized at the end of the transaction packet, need to be checked for overlaps as well as for gaps
The first two challenges just result in more bytes being used than would otherwise be used by the inline serialization approach. The third just results in some additional validation of the trailing data section in our transaction packet. However, this validation could be a simple incrementing counter to as the transaction is serialized or parsed.
The main benefit of this approach is that we can now iterate our instructions without needing to reparse the compressed u16s each time, while also using no additional memory for caching metadata about each instruction.
As a quick comparison, I wrote a simple bench which compares iteration of Vec<CompiledInstruction> in the legacy transaction format, the no-copy parsing using current serialization format, and the no-copy parsing using the proposed serialization format.
The results are as follows:
serialization format/CompiledInstruction Slice
time: [162.17 ns 162.90 ns 163.69 ns]
thrpt: [6.1090 Melem/s 6.1387 Melem/s 6.1663 Melem/s]
serialization format/CompiledInstruction Slice with Deserialization
time: [5.9373 µs 5.9636 µs 5.9880 µs]
thrpt: [167.00 Kelem/s 167.68 Kelem/s 168.43 Kelem/s]
serialization format/inline serialization
time: [564.79 ns 565.98 ns 567.23 ns]
thrpt: [1.7630 Melem/s 1.7668 Melem/s 1.7706 Melem/s]
serialization format/oob serialization
time: [164.46 ns 164.76 ns 165.16 ns]
thrpt: [6.0546 Melem/s 6.0695 Melem/s 6.0806 Melem/s]This benchmark is not perfect, but it shows that the proposed serialization format can iterate over the serialized instructions nearly as fast as an owned vector of CompiledInstructions.
This eliminates one of the main drawbacks of the zero-copy parsing strategy when using the current serialization format, and eliminates the need for storing additional metadata for each instruction.
And although the fastest iteration is still the owned Vec<CompiledInstruction>, getting that Vec requires us to do an allocation and copy the data during the initial deserialization - avoiding that allocation and copying is more beneficial for overall performance than the slightly faster iteration time.
Compressed U16s
The compressed u16s are another oddity in the current serialization format. This is a simple variable length integer encoding that can save space in the serialized data, but it comes at the cost of performance.
Without giving the full details of the encoding, the idea is that the most significant bit of each byte is set if there are more bytes to read. This means that a u16 can be represented in 1-3 bytes, depending on the value. However, it also slows down the parsing process, as we need to read each byte, check if the most significant bit is set, and then shift the value into place. For a single byte u16, this takes 4 operations:
- check that there is another byte to read
- read the next byte
- check if the most significant bit is set (no)
- return the value
For a two byte u16, this takes 8 operations:
- check that there is another byte to read
- read the next byte
- check if the most significant bit is set (yes)
- shift the value into place
- check that there is another byte to read
- read the next byte
- check if the most significant bit is set (no)
- return the value
This can be somewhat optimized, since for valid packets the lengths represented by these compressed u16s can never use more than 2 bytes; the maximum packet length is 1232 bytes, and so the maximum length of any array in our packet is at least smaller than 1232, which can be represented by 2 bytes in our encoding scheme. However, this is still significantly slower than just reading a fixed-size u16:
- check there are 2 bytes to read
- read the next 2 bytes, and return the value
Additionally, with the proposed format if we check there’s enough length for the entire array of CompiledInstructionOffsets, we can avoid the bounds checks for reading each u16. This can be done because once the array length is known the bounds check can be done once, and then we can read the entire array without needing to check the bounds for each element.
The benefit of these compressed u16s is that they can save space in the serialized data, but using them for internal lengths inside the CompiledInstruction and MessageAddressTableLookup structs is the most significant cost in terms of parsing performance.
If we move to the out-of-band serialization format, we could eliminate the need for these compressed u16s entirely, at the cost of a few bytes overhead per instruction and ATL.
Extending The Idea
There are some additional changes that could be made to the serialization format to reduce the impact of the increased size, though some may have consequences in terms of what transactions can do:
- Use
u8s for the lengths of account fields inMessageAddressLookupTable- There is a maximum of 256 accounts allowed, because the account indexing is done with a
u8 - There’s at least one static account in every transaction - the fee-payer
- This means the maximum number of accounts loaded via ATL is 255
- Yet we encode them with compressed u16s, so any table with more than 127 accounts will use 2 bytes
- This change would has no real impact today since the number of accounts in a sanitized transaction is less than or equal to 64
- There is a maximum of 256 accounts allowed, because the account indexing is done with a
- Use
u8s for the lengths of theCompiledInstructionfield:- There is currently no limit on the number of instructions, aside from the packet length
- As mentioned in SIMD-0160, there is a proposal to limit the number of instructions to 64 at sanitization time - this is because there is a runtime limit so any transaction with more than 64 instructions would fail execution.
- Use
u8s for the lengths of theaccountsfield inCompiledInstruction- There are technically no limits on the number of accounts per instruction, except for the packet length
- However, the number of unique accounts is limited to 256.
- This change does impose a limit that does not exist today, but I am unaware of any realistic program that would need more than 255 accounts in a single instruction 2
- Instead of tracking offset per instruction/ATL, only track counts.
- This forces us to iterate over the instructions/ATLs to get the offsets, but it does save bytes.
- At least our current uses only ever iterate over transactions
Results
I implemented the above changes as a proof of concept benchmark here. The results are as follows:
min sized transactions/VersionedTransaction
time: [216.26 µs 217.46 µs 218.64 µs]
thrpt: [4.6834 Melem/s 4.7089 Melem/s 4.7351 Melem/s]
min sized transactions/TransactionMeta
time: [4.1810 µs 4.2160 µs 4.2522 µs]
thrpt: [240.82 Melem/s 242.88 Melem/s 244.92 Melem/s]
min sized transactions/OOBTransactionMeta
time: [3.8429 µs 3.8468 µs 3.8504 µs]
thrpt: [265.94 Melem/s 266.19 Melem/s 266.47 Melem/s]
simple transfers/VersionedTransaction
time: [478.71 µs 480.05 µs 481.55 µs]
thrpt: [2.1265 Melem/s 2.1331 Melem/s 2.1391 Melem/s]
simple transfers/TransactionMeta
time: [6.1895 µs 6.2009 µs 6.2116 µs]
thrpt: [164.85 Melem/s 165.14 Melem/s 165.44 Melem/s]
simple transfers/OOBTransactionMeta
time: [4.6380 µs 4.6432 µs 4.6494 µs]
thrpt: [220.24 Melem/s 220.54 Melem/s 220.79 Melem/s]
packed transfers/VersionedTransaction
time: [6.2908 ms 6.3180 ms 6.3473 ms]
thrpt: [161.33 Kelem/s 162.08 Kelem/s 162.78 Kelem/s]
packed transfers/TransactionMeta
time: [235.04 µs 235.54 µs 236.12 µs]
thrpt: [4.3368 Melem/s 4.3475 Melem/s 4.3567 Melem/s]
packed transfers/OOBTransactionMeta
time: [39.726 µs 39.751 µs 39.787 µs]
thrpt: [25.737 Melem/s 25.760 Melem/s 25.777 Melem/s]
packed atls/VersionedTransaction
time: [3.5246 ms 3.5298 ms 3.5353 ms]
thrpt: [289.65 Kelem/s 290.10 Kelem/s 290.53 Kelem/s]
packed atls/TransactionMeta
time: [119.44 µs 119.68 µs 119.95 µs]
thrpt: [8.5372 Melem/s 8.5563 Melem/s 8.5734 Melem/s]
packed atls/OOBTransactionMeta
time: [19.939 µs 19.960 µs 19.980 µs]
thrpt: [51.250 Melem/s 51.303 Melem/s 51.357 Melem/s]In the worst case of packed transactions, the proposed format is nearly 6x faster than the zero-copy parsing of the current serialization format, and nearly 160x faster than the serde/bincode owned deserialization.
In the following table, the serialized size of the transaction is shown for each of the above benchmark cases:
| Benchmark | VersionedTransaction / TransactionMeta (B) | OOBTransactionMeta (B) |
|---|---|---|
| min sized transactions | 134 | 134 |
| simple transfers | 215 | 216 |
| packed transfers | 1218 | 1278 |
| packed atls | 1221 | 1223 |
The packet-size overhead seems low for such a significant performance improvement; however, the packed transfers and packed atls benchmarks are not very realistic. Though in the case of the packed transfers, a short-coming of the proposed format is clearly demonstrated - 1278 bytes is larger than the current packet size limit of 1232 bytes. This means that the proposed format would not be able to handle this 60-transfer transaction and would, in reality, only be able to fit 57 transfers.
Conclusion
The current serialization format is designed to be as compact as possible, but this comes at the cost of performance. The inline serialization of variable length types makes it difficult to iterate quickly without caching metadata, and compressed u16s is slow in general. In this post, a new serialization format was proposed that would allow for more efficient parsing, sanitization, and iteration of transactions while using no allocation or additional memory for caching metadata per instruction. In some cases this new serialization format would be larger; and considering egress costs are a significant factor for validators, this may not be a viable option. However, the performance improvements are significant, and the overhead of the new format is relatively low.
There are some additional changes that could be made to also reduce the size of serialized transactions, such as first-class resource requests - most transactions these days contain instructions for setting compute unit limits and prices. These could be supported as a field in the transaction format instead of being encoded as instructions - this would allow significant savings in the serialized size of transactions. While that might make the new format more competitive with the current format in terms of size, this change could also be made to the existing format to save the same amount of space.